
🦸🏻♂️ Introducing: Headless WordPress without WordPress
Ever since the Matt Mullenweg vs WPEngine debacle, I've noticed more and more people in Reddit (and elsewhere) asking for alternatives to WordPress, not necessarily to switch away from WordPress (at least not immediately), but to understand what options they have, and how painful would a potential migration be. They want to know how to hedge their bets.
For folks who are working with headless WordPress, Gato GraphQL now offers a cool new feature: Headless WordPress without WordPress.
This post explains all about it, describing how it is even possible, and showing a video demonstrating it.
Running Gato GraphQL as a standalone PHP app
Gato GraphQL has been built using standalone PHP components, managed via Composer, in such a way that all the PHP components making up the GraphQL server do not depend on WordPress!
As such, the GraphQL server can run as a standalone PHP application, and you can include it within any PHP application, based on WordPress or anything else.
If for some use case your application doesn't need to access WordPress data, then, at least for that use case, you are ready to go.
This video demonstrates such a use case: Interacting with GitHub's API, to download/install artifacts from GitHub Actions during development:
In the video, the GraphQL query executes an HTTP request to fetch the latest Gato GraphQL plugins generated in GitHub Actions, which are uploaded as artifacts when merging a pull request.
The URLs of the artifacts from the GraphQL response are then injected into WP-CLI, as to have the plugins automatically installed in a local DEV webserver, to run tests.
(I'll explain more in detail in the last section of this post.)
In this use case, as there is no WordPress data accessed at all, the GraphQL server can already run as a standalone PHP app.
If I needed to, I could even use it within my GitHub Actions workflow!
Migrating a headless WordPress app
Whenever you do access WordPress data, let's see how to run that without WordPress.
The GraphQL schema provided by Gato GraphQL contains fields to fetch WordPress data: posts, users, comments, tags, categories, etc.
The code in the PHP resolvers' fetching WordPress data depends on WordPress; that code cannot run on a non-WordPress app.
However, Gato GraphQL has each of these resolvers implemented via 2 packages:
- A "vanilla" PHP one, containing all generic code
- A WordPress-specific one, containing the actual invocations to WordPress methods that satisfy that resolver
For instance, in this GraphQL query:
{
posts {
id
title
}
}...the logic for fetching posts is composed of:
- The
Root.postsfield: It lives on the genericpostspackage - Its resolution for WordPress via the
get_postsmethod: It lives on the WordPress-specificposts-wppackage.
The code split between non-WordPress/WordPress packages is something around 80/20%, meaning that 80% of the code is reusable with another framework/CMS, and only 20% of the code would need to be reimplemented.
Moreover, all functionality in Gato GraphQL is shipped via modules, and modules can be enabled/disabled at will.
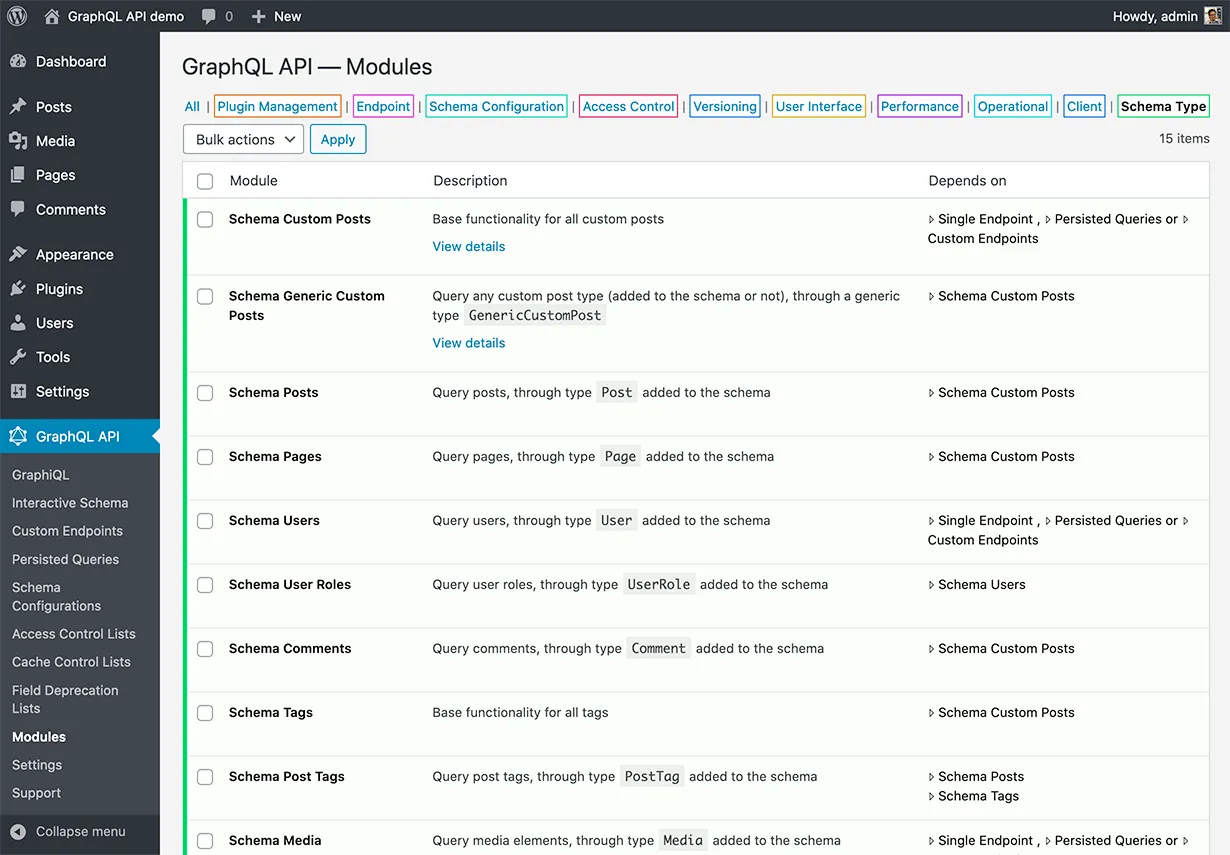
Modules is a feature implemented for security purposes: If you don't need to expose user data in your public API, then you can disable the Users module, and the corresponding fields (such as Root.users) will never be added to the schema.
Modules are directly mapped to underlying PHP packages. As such, when running Gato GraphQL as a standalone app, we can selectively load those modules/packages that we need, and none of the other ones.
For instance, if you application only prints data for posts, categories and tags, then only the posts-wp, categories-wp, and tags-wp packages (along with their dependencies) need to be loaded.
Then, when migrating away from WordPress (say, to Laravel, or Symfony), only those 3 WordPress-specific packages would need to be reimplemented for the new framework/CMS, and nothing else.
In consequence, you can use headless WordPress today, knowing that down the road you can migrate your application to another framework or CMS with minimal effort.
Transitioning to Gato GraphQL from another API
If you are already doing headless WordPress, chances are that your app is using either the WP REST API or WPGraphQL.
Unfortunately, with any of these two APIs you are locked to WordPress: There is no WP REST API outside of WordPress, and WPGraphQL cannot run without WordPress.
Fortunately, it is possible to swap either of them with Gato GraphQL, and gain the ability to migrate your headless WordPress app away from WordPress.
These 2 steps would then be needed:
- Transition from WP REST API or WPGraphQL to Gato GraphQL
- Reimplement the required WordPress-specific packages
Let's see how the API transition can be done.
WP REST API to Gato GraphQL's persisted queries
With the Persisted Queries extension you can publish REST-like endpoints, composed using GraphQL.
For each of the REST endpoints in your application, you can create a corresponding persisted query endpoint that retrieves the same data, and use that endpoint instead.
For instance, the following GraphQL query can replace REST endpoint /wp-json/wp/v2/posts/:
{
posts {
id
date: dateStr(format: "Y-m-d\\TH:i:s")
modified: modifiedDateStr(format: "Y-m-d\\TH:i:s")
slug
status
link: url
title: self {
rendered: title
}
content: self {
rendered: content
},
excerpt: self {
rendered: excerpt
}
author
featured_media: featuredImage
sticky: isSticky
categories
tags
}
}Thanks to the API hierarchy, the persisted query be published under path /graphql-query/wp/v2/posts/, making it easy to map endpoints.
To replicate REST endpoint /wp-json/wp/v2/posts/{id}/, which retrieves data for the post with given ID, we can provide the post ID under URL param postId.
For instance, the following persisted query can be invoked under endpoint /graphql-query/wp/v2/posts/single/?postId={id}:
query GetPost($postId: ID!) {
post(by: { id: $postId }) {
id
date: dateStr(format: "Y-m-d\\TH:i:s")
modified: modifiedDateStr(format: "Y-m-d\\TH:i:s")
slug
status
link: url
title: self {
rendered: title
}
content: self {
rendered: content
},
excerpt: self {
rendered: excerpt
}
author
featured_media: featuredImage
sticky: isSticky
categories
tags
}
}WPGraphQL to Gato GraphQL
The GraphQL schema from WPGraphQL and Gato GraphQL are similar but slightly different, so they need to be adapted.
The Next.js WordPress starter leoloso/next-wordpress-starter runs with either WPGraphQL or Gato GraphQL. The starter uses the same JS logic for either server, only the GraphQL queries are different.
This starter provides several examples of adapting the queries between the two servers. For instance, this WPGraphQL query:
fragment PostFields on Post {
id
categories {
edges {
node {
databaseId
id
name
slug
}
}
}
databaseId
date
isSticky
postId
slug
title
}...is adapted like this for Gato GraphQL:
fragment PostFields on Post {
id
categories: self {
edges: categories(pagination: { limit: -1 }) {
node: self {
databaseId: id
id
name
slug
}
}
}
databaseId: id
date: dateStr
isSticky
postId: id
slug
title
}In detail: Running Gato GraphQL as a standalone PHP app
Here is the in-detail explanation of the demo video from earlier on.
We provide the GraphQL query to run under file retrieve-github-artifacts.gql.
The query connects to the GitHub API by getting the access token from env var GITHUB_ACCESS_TOKEN. It dynamically generates the full path for the actions/artifacts endpoint from the provided variables, and then it sends an HTTP request against it.
From the response, it then extracts the "download URL" from within each artifact item, and sends asynchronous HTTP requests against them. From the Location header of each of these "download URLs", we obtain the actual URL of the downloadable file.
Finally, it prints all URLs together separated by a space, to make it convenient to inject into WP-CLI.
# File retrieve-github-artifacts.gql
query RetrieveProxyArtifactDownloadURLs(
$repoOwner: String!
$repoProject: String!
$perPage: Int = 1
$artifactName: String = ""
) {
githubAccessToken: _env(name: "GITHUB_ACCESS_TOKEN")
@remove
# Create the authorization header to send to GitHub
authorizationHeader: _sprintf(
string: "Bearer %s"
values: [$__githubAccessToken]
)
@remove
# Create the authorization header to send to GitHub
githubRequestHeaders: _echo(
value: [
{ name: "Accept", value: "application/vnd.github+json" }
{ name: "Authorization", value: $__authorizationHeader }
]
)
@remove
@export(as: "githubRequestHeaders")
githubAPIEndpoint: _sprintf(
string: "https://api.github.com/repos/%s/%s/actions/artifacts?per_page=%s&name=%s"
values: [$repoOwner, $repoProject, $perPage, $artifactName]
)
# Use the field from "Send HTTP Request Fields" to connect to GitHub
gitHubArtifactData: _sendJSONObjectItemHTTPRequest(
input: {
url: $__githubAPIEndpoint
options: { headers: $__githubRequestHeaders }
}
)
@remove
# Finally just extract the URL from within each "artifacts" item
gitHubProxyArtifactDownloadURLs: _objectProperty(
object: $__gitHubArtifactData
by: { key: "artifacts" }
)
@underEachArrayItem(passValueOnwardsAs: "artifactItem")
@applyField(
name: "_objectProperty"
arguments: { object: $artifactItem, by: { key: "archive_download_url" } }
setResultInResponse: true
)
@export(as: "gitHubProxyArtifactDownloadURLs")
}
query CreateHTTPRequestInputs
@depends(on: "RetrieveProxyArtifactDownloadURLs")
{
httpRequestInputs: _echo(value: $gitHubProxyArtifactDownloadURLs)
@underEachArrayItem(passValueOnwardsAs: "url")
@applyField(
name: "_objectAddEntry"
arguments: {
object: {
options: { headers: $githubRequestHeaders, allowRedirects: null }
}
key: "url"
value: $url
}
setResultInResponse: true
)
@export(as: "httpRequestInputs")
@remove
}
query RetrieveActualArtifactDownloadURLs
@depends(on: "CreateHTTPRequestInputs")
{
_sendHTTPRequests(inputs: $httpRequestInputs) {
artifactDownloadURL: header(name: "Location")
@export(as: "artifactDownloadURLs", type: LIST)
}
}
query PrintSpaceSeparatedArtifactDownloadURLs
@depends(on: "RetrieveActualArtifactDownloadURLs")
{
spaceSeparatedArtifactDownloadURLs: _arrayJoin(
array: $artifactDownloadURLs
separator: " "
)
}The PHP logic directly loads the code from the Gato GraphQL plugin, and from the “Power Extensions” bundle (needed to send HTTP requests, and other functionality).
As a standalone PHP app, we must explicitly indicate what modules are initialized, and provide any non-default configuration.
For instance, we tell module SendHTTPRequests to allow connecting to https://api.github.com/repos, and module EnvironmentFields to allow accessing environment variable GITHUB_ACCESS_TOKEN.
Notice that the GraphQL schema is generated the first time the GraphQL query is executed, and cached to disk. This way, from the 2nd time onwards, none of the code to compute the schema is executed, making the execution faster.
Finally, the standalone app initializes the GraphQL server, executes the query against it, and prints the response.
<?php
// File retrieve-github-artifacts.php
declare(strict_types=1);
use GraphQLByPoP\GraphQLServer\Server\StandaloneGraphQLServer;
use PoP\Root\Container\ContainerCacheConfiguration;
// Load the GraphQL server via the standalone PHP components
require_once (__DIR__ . '/wordpress/wp-content/plugins/gatographql/vendor/scoper-autoload.php');
// Load the PRO extensions via the standalone PHP components
require_once (__DIR__ . '/wordpress/wp-content/plugins/gatographql-power-extensions-bundle/vendor/scoper-autoload.php');
// Modules required in the GraphQL query
$moduleClasses = [
\PoPSchema\EnvironmentFields\Module::class,
\PoPSchema\FunctionFields\Module::class,
\GraphQLByPoP\ExportDirective\Module::class,
\GraphQLByPoP\DependsOnOperationsDirective\Module::class,
\GraphQLByPoP\RemoveDirective\Module::class,
\PoPSchema\ApplyFieldDirective\Module::class,
\PoPSchema\SendHTTPRequests\Module::class,
\PoPSchema\ConditionalMetaDirectives\Module::class,
\PoPSchema\DataIterationMetaDirectives\Module::class,
];
// Configure the modules
$moduleClassConfiguration = [
\PoP\GraphQLParser\Module::class => [
\PoP\GraphQLParser\Environment::ENABLE_MULTIPLE_QUERY_EXECUTION => true,
\PoP\GraphQLParser\Environment::USE_LAST_OPERATION_IN_DOCUMENT_FOR_MULTIPLE_QUERY_EXECUTION_WHEN_OPERATION_NAME_NOT_PROVIDED => true,
\PoP\GraphQLParser\Environment::ENABLE_RESOLVED_FIELD_VARIABLE_REFERENCES => true,
\PoP\GraphQLParser\Environment::ENABLE_COMPOSABLE_DIRECTIVES => true,
],
\PoPSchema\SendHTTPRequests\Module::class => [
\PoPSchema\SendHTTPRequests\Environment::SEND_HTTP_REQUEST_URL_ENTRIES => [
'#https://api.github.com/repos/(.*)#',
],
],
\PoPSchema\EnvironmentFields\Module::class => [
\PoPSchema\EnvironmentFields\Environment::ENVIRONMENT_VARIABLE_OR_PHP_CONSTANT_ENTRIES => [
'GITHUB_ACCESS_TOKEN',
],
],
];
// Cache the schema to disk, to speed-up execution from the 2nd time onwards
$containerCacheConfiguration = new ContainerCacheConfiguration('MyGraphQLServer', true, 'retrieve-github-artifacts', __DIR__ . '/tmp');
// Initialize the server
$graphQLServer = new StandaloneGraphQLServer($moduleClasses, $moduleClassConfiguration, [], [], $containerCacheConfiguration);
/**
* GraphQL query to execute, stored in its own .gql file
*
* @var string
*/
$query = file_get_contents(__DIR__ . '/retrieve-github-artifacts.gql');
// GraphQL variables
$variables = [
'repoOwner' => 'GatoGraphQL',
'repoProject' => 'GatoGraphQL',
'perPage' => 3
];
// Execute the query
$response = $graphQLServer->execute(
$query,
$variables,
);
// Print the response
echo $response->getContent();To execute the GraphQL query, we run in the terminal (using jq to pretty print the JSON output):
php retrieve-github-artifacts.php | jqFinally, to extract the artifact URLs from the GraphQL response, and inject them into WP-CLI, we run:
GITHUB_ARTIFACT_URLS=$(php retrieve-github-artifacts.php \
| grep -E -o '"spaceSeparatedArtifactDownloadURLs\":"(.*)"' \
| cut -d':' -f2- | cut -d'"' -f2- | rev | cut -d'"' -f2- | rev \
| sed 's/\\\//\//g')
wp plugin install ${GITHUB_ARTIFACT_URLS} --force --activateAs shown in the video, we are able to execute Gato GraphQL without WordPress.